직렬화(Serialization)
Airflow의 DAG 직렬화를 알아보기 전에, 직렬화가 무엇인지부터 정리해보려고 합니다.
우리가 어떤 객체 데이터를 가지고 저장하거나 통신한다고 가정해보겠습니다.
실제 실행중인 프로세스상에서 데이터는 연속적이지 않게 메모리에 퍼져 있습니다. 물론 프로세스를 메모리에 연속된 주소로 할당하는 기법도 있긴 하지만, 단편화 문제도 있고, 가장 크게는 메모리 크기를 넘어서는 프로세스는 실행할 수 없다는 치명적인 문제가 있어서 사용하지 않고 있으니 요 친구는 논외로 하겠습니다. 그러니 앞서 말씀드린 것처럼, 객체 데이터는 비연속적으로 퍼져 있다고 볼 수 있습니다.
이런 객체 데이터를 가지고 통신하거나 저장하려면, 그 객체 데이터 그대로를 사용해서는 불가능합니다. 메모리 주솟값 등등 고려해야 할 것도 너무 많고, 이 형태 그대로는 다른 환경(저장 공간, 다른 프로세스)에선 사용할 수 없습니다.
이를 해결하기 위해 직렬화(Serialization)가 등장합니다. 직렬화는 데이터 구조나 오브젝트의 상태를, 동일하거나 다른 환경에 저장하고 나중에 재구성할 수 있는 포맷으로 변환하는 과정입니다. 좀 더 프로그래밍 언어가 하는 일에 가깝게 풀자면, 객체의 내용을 바이트 단위 배열로 변환하여, 파일 또는 네트워크를 통해 스트림(송수신)이 가능하게 하는 것을 의미합니다.
만약 직렬화된 데이터를 수신 또는 저장한 후에, 이를 객체로 다시 사용하려면, 역직렬화(Deserialization) 과정을 거쳐주면 됩니다.
여담이지만, 직렬화는 마샬링(Marshaling) 한다고도 표현합니다. Golang에서는 이 용어로 사용되고 있었던 게 생각나네요. (역직렬화는 Unmarshaling)
그렇다면 이제 Airflow DAG를 직렬화하는 이유는 무엇인지 알아보겠습니다.
Airflow DAG 직렬화
DAG 직렬화가 없고, Meadata DB를 사용하지 않던 때에는, 아래 좌측 이미지처럼, Webserver와 Scheduler 모두가 DAG 파일에 직접 접근해서 DAG를 파싱해와야 했습니다. 이는 같은 작업(DAG 파싱)을 반복해야만 하는 문제가 있었습니다.
또한, 이러한 DAG 파싱 작업은 Webserver가 새로 시작되는 경우에, 다시 수행해야 하므로(파싱한 DAG를 들고 있어야 하기 때문 = Stateful) Webserver의 로딩 타임과 메모리를 키우는 주요 원인이기도 했습니다.
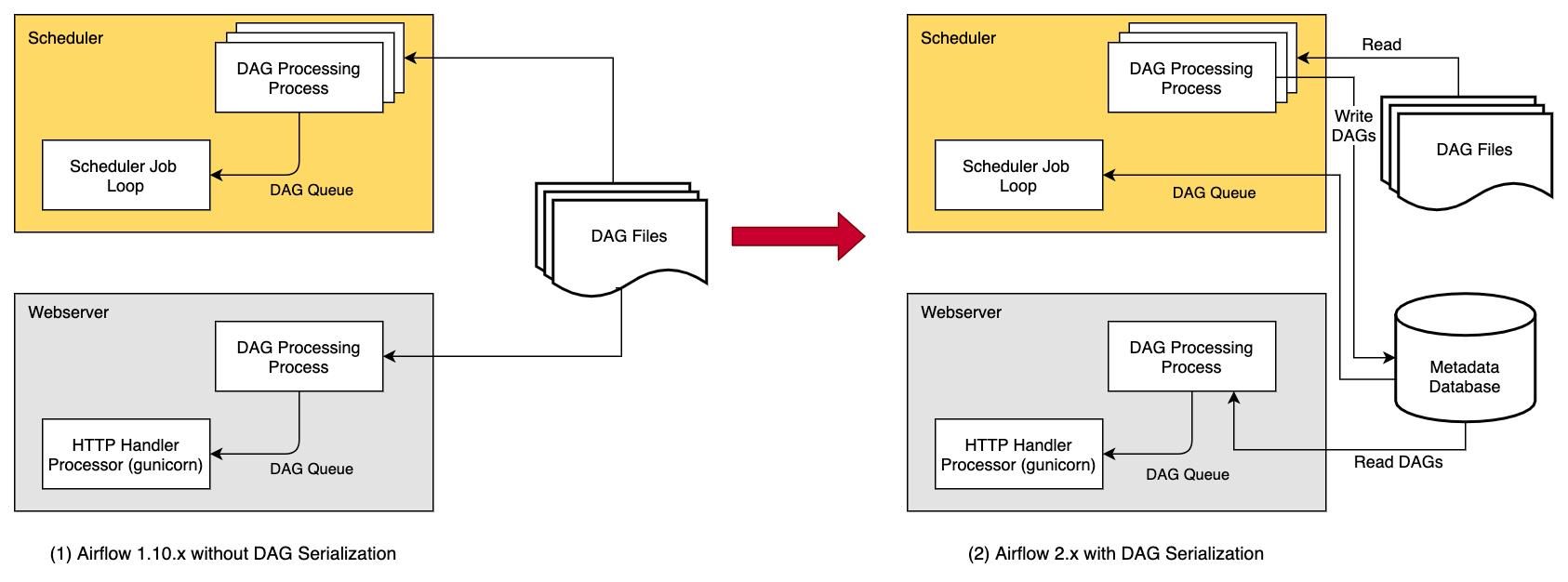
이러한 문제를 해결하고자, Airflow에서도 1.10.7 이상부터 DAG를 직렬화해서 이용하는 것을 지원하고 있습니다. 특히 Airflow 2.0.0 이상부터는 DAG 직렬화 옵션은 비활성화할 수 없습니다. 이는 Airflow Webserver를 Stateless하게 만듭니다. 여담으로, Airflow 2.0.0 이상부터는 scheduler도 일관성을 위해 직렬화된 DAG를 사용하여 스케줄링을 수행합니다.
DAG를 직렬화하게 되면, 이젠 Webserver를 DAG 파싱 작업에서 분리하여 매우 가볍게 만들 수 있습니다. DAG 파싱 작업은 Scheduler에서만 수행하게 됩니다. Scheduler에서 DagFileProcessorProcess가 DAG 파일을 파싱하여 JSON 형식으로 직렬화하고, 이를 Metadata DB에 SerializedDagModel 모델로 저장합니다.
그러면, webserver는 DAG 파일을 다시 파싱하는 대신에, JSON으로 직렬화된 DAG를 읽고, 이를 역직렬화해서 DagBag을 생성한 다음 이를 가지고 UI에 나타내 줍니다.
또한 Scheduler도, 스케줄링을 수행하는 데에 실제 DAG 파일이 필요하지 않습니다. Airflow 2.0.0부터는 DAG를 스케줄링하는 데에 필요한 정보도 포함해서 DAG를 직렬화하기 때문입니다.
DAG 직렬화를 사용하게 됨으로써 얻는 가장 큰 이점 중 하나는 Webserver가 시작될 때, 매번 전체 DagBag을 로드하는 대신에, 필요한 DAG에 대해서만 직렬화된 DAG 테이블에서 로드한다는 점입니다. 이는 곧, Webserver의 시작 시각과 메모리를 줄이는 데에 도움이 되며, 특히 많은 DAG가 존재할 때 눈에 띄는 향상을 보여줍니다.
관련 설정
DAG 직렬화와 관련된 설정을 변경하려면 airflow.cfg 에서 다음 key를 확인합니다.
[core]
min_serialized_dag_update_interval = 30
min_serialized_dag_fetch_interval = 10
max_num_rendered_ti_fields_per_task = 30
compress_serialized_dags = Falsemin_serialized_dag_update_interval: 이 옵션은 DB에 저장된 직렬화된 DAG가 업데이트되어야 하는 최소 주기(초)를 설정합니다. DB 쓰기 속도를 제어하는 데에 도움을 줍니다.min_serialized_dag_fetch_interval: 이 옵션은 직렬화된 DAG가 Webserver의 DagBag에 이미 로드되어 있을 때, DB에서 다시 가져오는 주기를 설정합니다. 이 값을 높게 설정하면 (당연하게도) DB에 가해지는 부하는 줄어들지만, DAG의 현재 버전이 아닌 이전에 캐싱 된 오래된 버전이 보일 수 있습니다.max_num_rendered_ti_fields_per_task: 이 옵션은 DB에 저장할 Task당 Rendered Task Instance Fields (Template Fields) 의 최대 개수를 설정합니다. (execution_date나, 해당 시점에 입력되는 동적 변수들을 담아 렌더링한 인스턴스를 의미하는 것으로 보입니다)compress_serialized_dags: 이 옵션은 직렬화된 DAG를 DB에 적재할 때 압축 여부를 결정합니다. 이 옵션은 클러스터 내에 매우 큰 DAG들이 존재하는 경우 유용합니다. 다만, 이 옵션이True로 설정되면, DAG 종속성 보기(DAG dependencies view) 가 비활성화됩니다.
참고
- https://airflow.apache.org/docs/apache-airflow/stable/dag-serialization.html
- https://study-for-me.tistory.com/10
- https://ko.wikipedia.org/wiki/직렬화
- https://lordofkangs.tistory.com/203
마무리
Airflow 2.3.0의 릴리즈 문서를 정리하면서 포스트를 작성하던 와중에 airflow dags reserialize 커맨드가 새로 추가되었다는 내용을 보게 되었습니다. Serialize에 대해서도 잘 모르는 와중에 Reserialize 내용을 작성할 수는 없겠다 싶어서 간단하게 정리해보았습니다. 추후 Airflow 2.3.0 릴리즈를 소개하는 내용으로 이어가겠습니다.
만약 이 글이 도움이 되셨다면 글 좌측 하단의 하트❤를 눌러주시면 감사하겠습니다.
혹시라도 글에 이상이 있거나, 오역, 이상한 번역이 있거나, 이해가 가지 않으시는 부분, 또는 추가로 궁금하신 내용이 있다면 주저하지 마시고 댓글💬을 남겨주세요! 빠른 시간 안에 답변을 드리겠습니다 😊
'IT > Airflow' 카테고리의 다른 글
| [Airflow] Backfill과 Clear를 정리해보자 (0) | 2022.09.18 |
|---|---|
| [Airflow] PythonSensor에 pod override 옵션 적용하기 (0) | 2022.09.04 |
| [Airflow] Pool (0) | 2022.07.09 |
| [Airflow] Dynamic Task Mapping (동적 태스크 매핑) (0) | 2022.06.06 |
| [Airflow] Sensor를 정리해보자 (2) | 2022.05.22 |