Introduction
최근 사내에서 사용하는 몇몇 Airflow 클러스터 관리를 담당하게 되면서 Airflow 2.3.0으로의 버전업을 진행하게 되었습니다. 사실 이전에 다뤘던 두 포스트도 그 일환으로 작성했던 내용이네요 ㅎㅎ
Airflow 2.3.0 업그레이드에는 나름 큰(?) 변경 사항과 추가 사항이 있습니다. 그동안 사용해왔던 TreeView를 대체하는 GridView의 도입, LocalKubernetesExecutor의 도입, 메타데이터 DB에 쌓여만 가던 오래된 데이터를 지워주는 airflow db clean 명령어 등, 각각 하나의 글로 작성해도 충분할만큼 중요한 신규 기능, 변경점들입니다.
그중에서도 가장 주목 받았던 신규 기능이라고 한다면, Dynamic Task Mapping 을 꼽을 수 있겠네요! 왜 그런지는.. 이제부터 파악해보려구요 ㅋㅋㅋ
Dynamic Task Mapping이 도입되면서 런타임에 동적으로 병렬 Task를 생성하는 DAG를 작성할 수 있게 되었습니다! Airflow 2.3.0 이전까지는 DAG가 파싱되는 시점에만 동적으로 Task를 생성할 수 있었습니다. 말인 즉슨, DAG 파싱 시점 이후에 변경된 외부 요소가 있다면, 이건 반영되지 않는다는 것이죠. 이런 어려움을, Dynamic Task Mapping과 함께라면 해결할 수 있습니다. DAG가 현재 런타임 시점의 환경을 기반으로 Task를 생성하게 되었기 때문입니다.
사실 여기까지만 들어도, 왜 가장 주목받았던 신규 기능인지는 이미 파악이 된 거 같습니다. 그럼 좀 더 자세히 알아볼까요!
Dynamic Task 컨셉
Airflow의 Dynamic Task Mapping 기능은 MapReduce 모델을 기반으로 하고 있습니다. 최근 들어 Hadoop 스터디를 하면서도 MapReduce를 마주쳤는데, 여기서도 보게 되니 반갑네요!
Map은 일련의 Input Data를 받아서, 각각에 대해 단일 작업을 생성합니다. Reduce는 Map 작업을 통해 만들어진 결과물을 가지고 연산을 수행합니다. Map은 필수적으로 작업이 이뤄져야 하지만, Reduce는 그렇지는 않습니다. 흔히 Map은 Transformation, Reduce는 Action으로 표현합니다. 말 그대로, 데이터를 연산하기에 좋은 형태로 변형하는 작업이 Map이고, 그렇게 만들어진 형태의 데이터를 갖고 연산하는 것을 Reduce라고 보면 됩니다.
Airflow에 연관지어 이야기해보면 다음과 같습니다.
- Map : 런타임에 DAG가, 몇몇 입력 파라미터를 기반으로 임의의 개수만큼 병렬 Task를 생성할 수 있음을 의미합니다.
- Reduce : 그리고 만약 필요하다면, Map 과정에서 만들어진 결과물을 기반으로 병렬적으로 Mapping 된 단일 Task의 다운스트림을 생성할 수 있음을 의미합니다.
Dynamic Task Mapping의 “map” 부분을 구현하기 위해 Airflow Task는 두 가지 새로운 함수를 제공합니다. 여러분이 Map 하고자 하는 Task엔, 모든 operator 파라미터가, 다음 두 함수 중 하나를 통해 반드시 전달되어야 합니다.
expand(): 이 함수는 mapping하고자 하는 파라미터를 전달합니다. 각 입력 값에 대해 별도의 병렬 Task가 생성됩니다.partial(): 이 함수는expand()함수로 생성된 모든 mapped Task에 일정하게 유지되는 파라미터를 전달합니다.
다음 코드에 정의된 Task는 동적으로 3개의 Task를 실행하기 위해 위 두 가지 함수를 모두 사용하는 예제입니다.
@task
def add(x: int, y: int):
return x+y
added_values = add.partial(y=10).expand(x=[1,2,3])
# add 함수의 결과는 다음처럼 expand 됩니다.
# add(x=1, y=10)
# add(x=2, y=10)
# add(x=3, y=10)이 expand() 함수는 세 개의 mapped add Task를 생성합니다. 그리고 그 세 개의 Task는 각각 x 에 대한 값으로 입력 리스트에 있는 값을 하나씩 갖도록 합니다. (예제의 경우, 각각 1, 2, 3을 하나씩 갖는다고 보면 됩니다.) 그리고 partial() 함수는 세 개의 Task에 대해 남은 값인 y 값을 지정해주고 있습니다.
이렇게 mapped Task를 가지고 작업할 땐, 몇 가지 명심해야 할 점이 있습니다.
이제 업스트림 Task의 결과를 Mapped Task에 대한 입력 값으로 사용할 수 있습니다 (이건 Dynamic Task Mapping 기능이 엄청난 기능임을 보여주는 이유이기도 합니다) 업스트림 Task는 반드시
dict또는list의 형태로 결과를 리턴해야 합니다. 만약 decorator task가 아닌 구 operator를 사용한다면, mapping 값은 XCom에 반드시 보관해야 합니다. (아래이전 스타일의 operator ...내용에서 소개된 예제를 참조해주세요)단일 파라미터 뿐만 아니라,
expand()를 위해서 여러 개의 파라미터를 전달할 수도 있습니다. 이렇게 하면, 각 파라미터의 조합으로 mapped Task을 호출하는 “외적(cross product)” 을 생성하는 결과를 만듭니다.@task def add(x: int, y: int): return x + y added_values = add.expand(x=[2, 4, 8], y=[5, 10]) # 이렇게 하면 add 함수가 다음처럼 호출되는 결과를 만듭니다. # add(x=2, y=5) # add(x=2, y=10) # add(x=4, y=5) # add(x=4, y=10) # add(x=8, y=5) # add(x=8, y=10)mapped Task의 결과물을 다운스트림 mapped Task의 입력값으로 활용할 수 있습니다.
아무 Task Instance도 생성하지 않는 mapped Task가 있을 수도 있습니다. (예를 들어, mapping 값을 생성하는 업스트림 Task가 빈 리스트를 리턴했을 때) 이 경우에는, mapped Task가
skipped로 마킹되며, 다운스트림 Task는 설정된 Trigger Rule에 따라 진행됩니다. (아무런 설정을 하지 않았다면, 다운스트림 또한skipped로 마킹됩니다.)이전 스타일의 operator 에 대해서도
partial과expand을 사용할 수 있습니다. 다만 일부 파라미터는 mappable 하지 않으므로, 반드시partial()함수를 통해 전달되어야 합니다. 예를 들어,task_id,pool그리고 대부분의BaseOperator에 사용되는 인자들이 이에 해당합니다.BashOperator.partial(task_id="bash", do_xcom_push=False).expand( bash_command=["echo 1", "echo 2"] )
Use Case
Dynamic Task Mapping 은 그 활용도가 무궁무진합니다. 대표적으로는 ELT 또는 ML Ops 등에 활용할 수 있습니다.
ELT
예를 들어, S3 파일에서 데이터를 추출하고, 이 데이터를 Snowflake에 로드하고, Snowflake는 연산을 수행해서 데이터를 변환하는 ELT 파이프라인이 있다고 가정할 때, S3 버킷에는 얼마나 많은 파일이 존재하는지 알 수 없습니다. 파일의 개수는 그날 그날 다르기 때문입니다. 이런 상황에서, 런타임 시점에 파일의 개수만큼 동적으로 Task를 만들어줄 수 있으면 훨씬 더 쉬운 파이프라인 관리, atomicity를 제공해줄 수 있겠죠! 이런 상황에서 Dynamic Task Mapping이 사용될 수 있습니다.
ML Ops
ML Ops에선 동적으로 변하는 컴포넌트가 포함되는 경우가 많습니다. 다음의 사례에서 유용하게 사용할 수 있습니다.
- 서로 다른 모델을 학습시키기 : 모델마다 별도의 DAG를 작성할 필요가 없습니다. 모델 리스트가 주기적으로 변경되더라도, Dynamic Task Mapping을 활용하면, 사용자가 개입하지 않아도, 각 모델마다 작업을 진행해줍니다. 그리고 모델 리스트에서 빠진 과거의 모델에 대해서도 히스토리를 유지해줍니다.
- 모델에 대해 Hyperparameter 학습 진행하기 : 최상의 파라미터 집합을 통해 얻은 결과물을 배포하기 전에 하이퍼파라미터 튜닝을 진행하고 싶은 단일 모델이 있을 때 활용할 수 있습니다. Dynamic Task Mapping을 활용하게 되면, 런타임 시점에 외부 시스템으로부터 필요한 파라미터를 가져와 활용할 수 있기 때문에 작업을 유연하게 진행할 수 있습니다.
- 고객별로 다른 모델 생성하기 : 각 고객마다 별도로 학습을 진행해야 하는 모델이 있습니다. 특히 고객 리스트는 자주 변경될 수 있고, 이전 고객에 대해서도 그 히스토리를 유지해야 합니다. Dynamic Task Mapping 이전에는 삭제된 고객에 대해서 히스토리를 유지할 방법이 없었습니다. 하지만 이제는 매번 동적으로 고객 리스트를 처리할 수 있게 되어, 단일 DAG 하나만으로도 학습을 진행할 수 있고, 매번 바뀌는 고객 리스트에서 히스토리 유지도 가능하게 되었습니다.
예제 DAG
이번에는 직접 DAG를 작성해서 어떻게 실행되는지 한번 살펴보겠습니다. 아래 예제는 위에서 활용했던 add Task에 print Task를 연결해서 만들어진 value list를 로깅하는 단순한 DAG 코드입니다.
import logging
from datetime import datetime
from airflow import DAG
from airflow.decorators import task
with DAG(dag_id="sample_repeated_mapping",
start_date=datetime(2022, 6, 4),
catchup=False
) as dag:
@task
def add(x: int, y: int):
return x + y
@task
def print_x(x: list):
logging.info(x)
added_values = add.expand(x=[2, 4, 8], y=[5, 10])
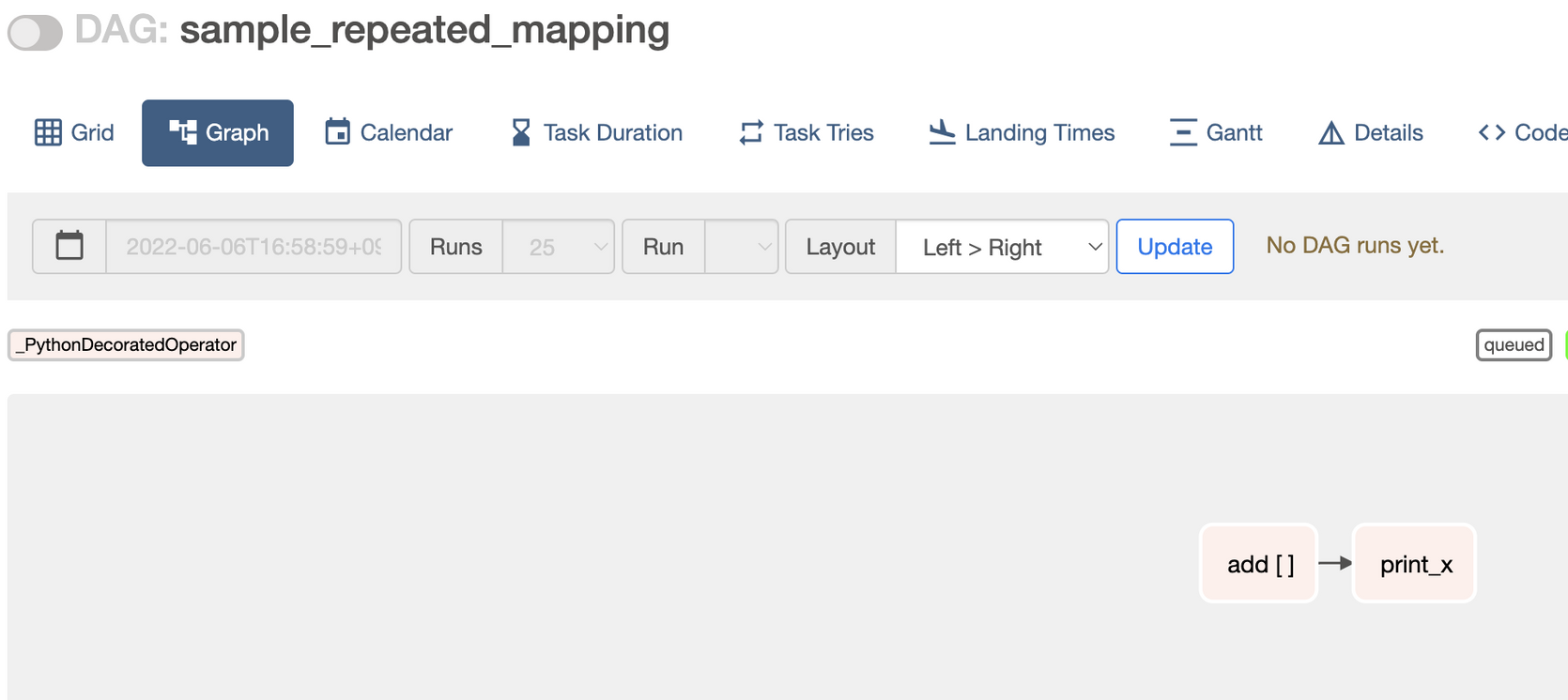
print_x(added_values)위 DAG는 Airflow UI에서 어떻게 표현될까요? Graph View에서 보면, 모든 mapped Task는 task_id 옆에 [ ] 처럼 대괄호 쌍이 표시됩니다. 아래 이미지에서 보면 add [] 로 나타나고 있습니다.
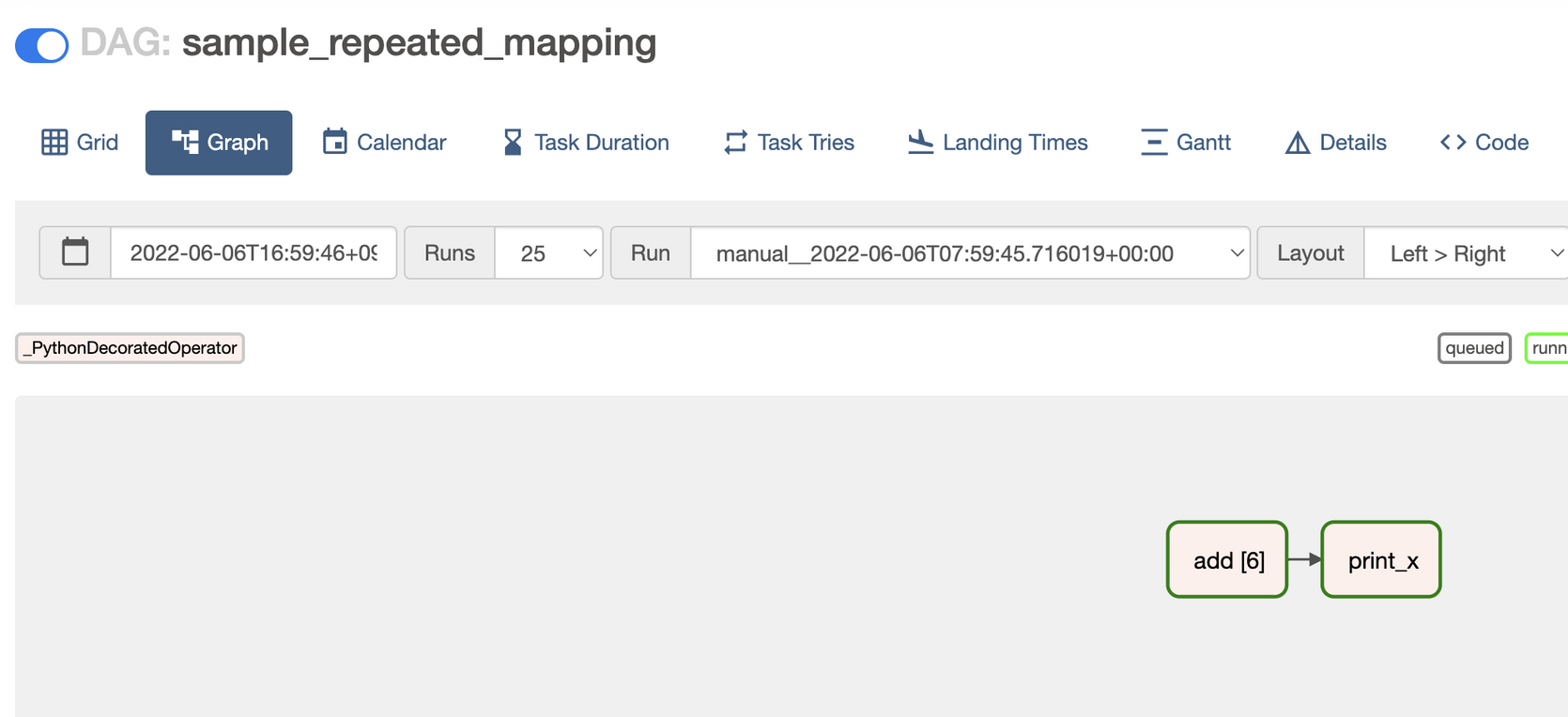
이 DAG를 실행하면, 대괄호 안에는 동적으로 생성된 mapped Task Instacne의 개수가 표시됩니다. 아래는 이미지를 보면 add [6] 처럼 나타난 것을 볼 수 있습니다. 이 개수는 동적으로 생성되기 때문에 매번 달라질 수 있습니다.
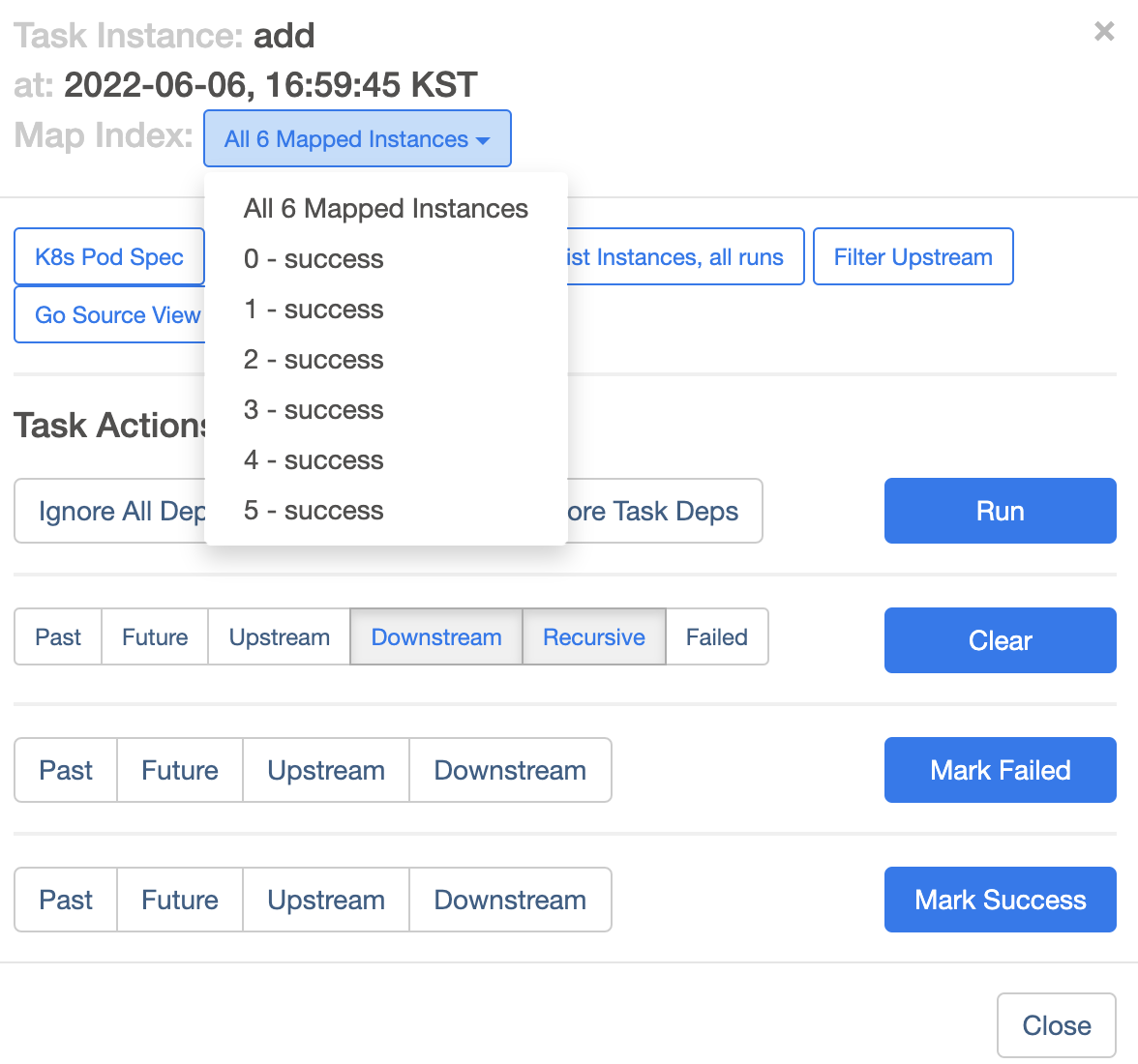
또한 해당 Task를 눌러보면, 각각의 mapped Task Instance를 살펴볼 수 있도록 아래처럼 하나씩 선택해서 볼 수 있습니다.
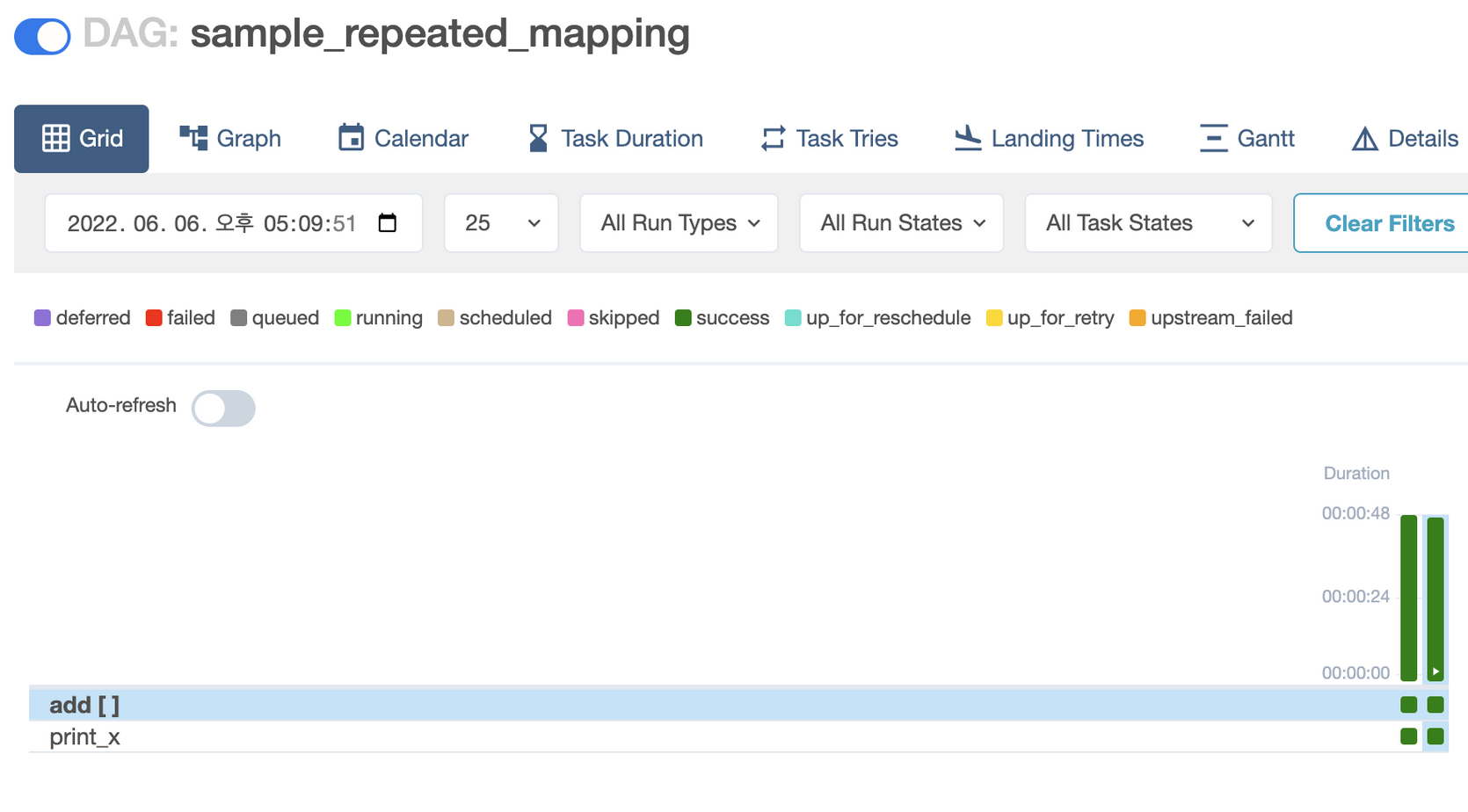
Airflow 2.3.0 부터 변경된 Grid View에서도 다음처럼 mapped Instance가 무엇인지 볼 수 있습니다.
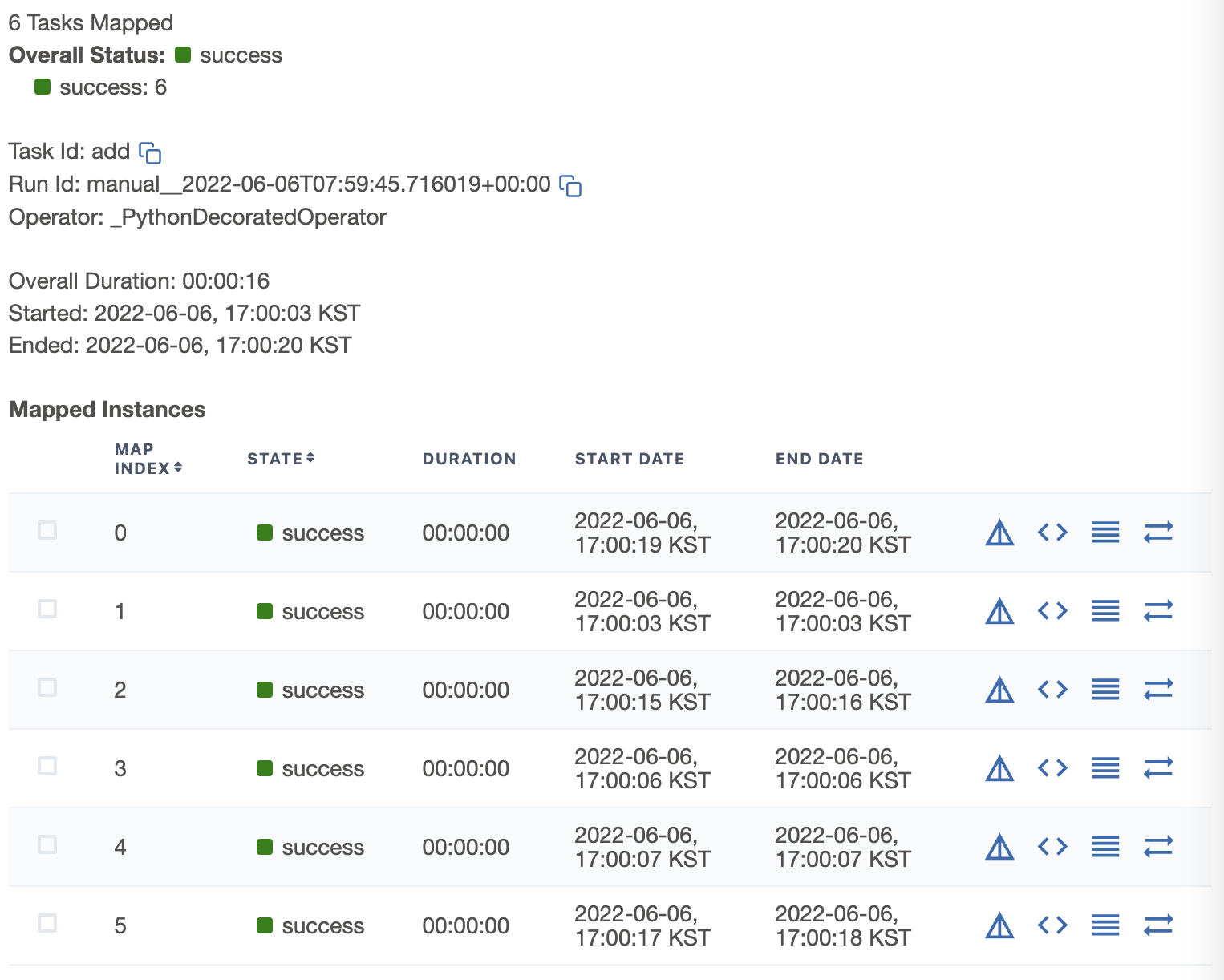
mapped Task의 Detail Panel을 보게 되면 mapped Task Instance의 리스트도 한 눈에 볼 수 있습니다.
마무리
최근 들어 Airflow 2.3.x 를 다룰 일이 많네요. 그리고 새로운 기능에 대해서도 하나하나 알아가보는 중에 만나게 된 Dynamic Task Mapping에 대해 알아보는 글을 작성해보았습니다. 추후 Airflow 2.3.0 릴리즈를 소개하는 내용으로 이어가겠습니다.
만약 이 글이 도움이 되셨다면 글 좌측 하단의 하트❤를 눌러주시면 감사하겠습니다.
혹시라도 글에 이상이 있거나, 이상한 번역이 있거나, 이해가 가지 않으시는 부분, 또는 추가적으로 궁금하신 내용이 있다면 주저 마시고 댓글💬을 남겨주세요! 빠른 시간 안에 답변을 드리겠습니다 😊
참고
'IT > Airflow' 카테고리의 다른 글
| [Airflow] Backfill과 Clear를 정리해보자 (0) | 2022.09.18 |
|---|---|
| [Airflow] PythonSensor에 pod override 옵션 적용하기 (0) | 2022.09.04 |
| [Airflow] Pool (0) | 2022.07.09 |
| [Airflow] Sensor를 정리해보자 (2) | 2022.05.22 |
| [Airflow] Airflow DAG Serialization (직렬화) (0) | 2022.05.08 |